Attention is all you need.
Transformer 架构
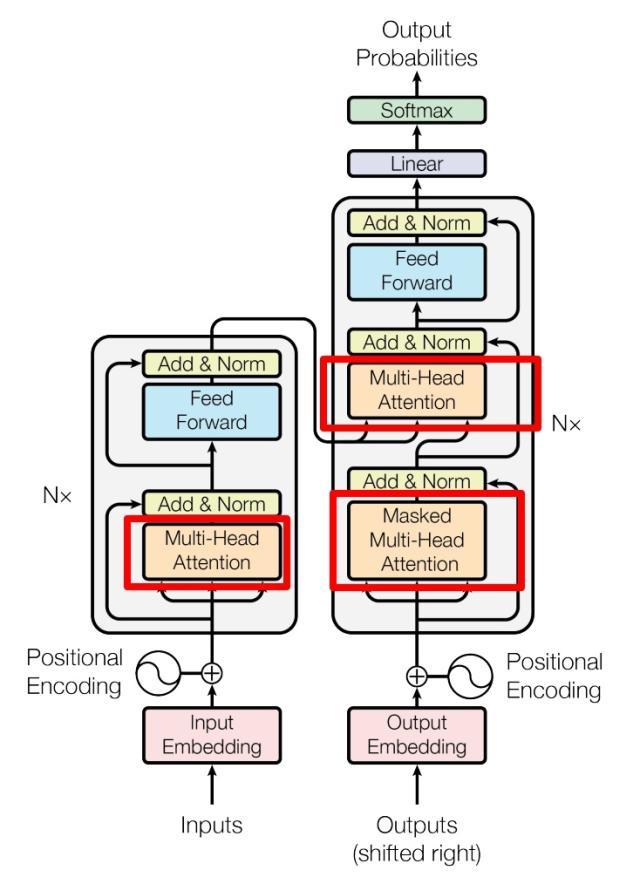
Transformer 的整体架构由
位置编码 Positional Encoding
对于每一个词嵌入向量,我们将其与一个矩阵进行拼接,使词向量具有其文本位置的信息。Vaswani 等人在 Transformer 原始论文中提出的方案,位置编码矩阵是通过三角函数公式计算得到的固定值,不参与模型训练。它的核心优势是可以处理任意长度的序列(超出训练时的最大长度也能生成对应的编码)。
设向量维度为
通过原词向量与
自注意力机制 Self-Attention
该机制意在处理文本中的上下文关联,让词向量包含其临近词语的信息。
设计线性变换矩阵
其中
据此,我们可以计算出注意力值:
除以
多头注意力 Multi-Head Attention
将嵌入矩阵
拼接(Concatenation)和线性变换(Linear)是什么?
对于矩阵
称
在 Multi-Head Attention 中,
Linear 指的是未确定矩阵
Encoder 结构
残差连接 Residual Connection
经过多头处理得到
也就是将多头处理后的
层归一化 Layer Normalization
Layer Normalization(简称 LN)是深度学习中一种特征归一化技术,由 Jimmy Lei Ba、Jamie Ryan Kiros 和 Geoffrey Hinton 于 2016 年在论文《Layer Normalization》中提出。它的核心思想是对单个样本的所有特征维度进行归一化处理,适用于 RNN、Transformer 等序列模型和小批量训练场景。
Norm 的作用是将词向量
其中
更平凡地,可以写成:
来调整想要得到的均值和方差。一般
Feed Forward
一个两层的全连接层,第一层激活函数为
处理后加上 Add & Norm。
Decoder 结构
Decoder 由两个 Multi-Head Attention 和一个 Feed Forward 组成,其中第一个 Multi-Head 使用了 Masked。
掩码 Masked
据一般的理解,文字的工作具有很强的顺序性,也就是当你在处理第
信息传输
Decoder 的第二个 Multi-Head Attention 中使用的
Output 结构
Decoder 执行完毕后,我们会得到一个嵌入矩阵
之后对
Vision Transformer
ViT,将 Transformer 用于计算机视觉上的运用。
图像块 Image Patches
ViT 首先将输入图像切分为多个固定大小的图像块(Patches)。这些图像块被线性嵌入到固定大小的向量中,类似于 NLP 中的单词嵌入。每个图像块都被视为一个独立的“视觉单词”或 token,并用于后续的 Transformer 层中进行处理。
Transformer 编码器
与 NLP 中一致,ViT 同样使用了 Positional Embedding 和 Multi-Head Attention 机制。并在子层后用到了 Add & Norm 进行训练优化。在之间也同样会有 Masked 和 Dropout 等策略。
在 MHSA 后仍然会跟一个 MLP Block 的两层全连接层,激活函数一般使用
分类令牌 Class Token
在输入时,ViT 一共需要
cls_token 最开始是一个随机初始化的
在输出分类特征时,ViT 会仅提取最终层的 cls_token 向量,完全舍弃所有 Patch Token—— 因为此时的 cls_token 已承载全图全局特征,而 Patch Token 仍仅保留局部特征,无单独分类价值。
分类头 Classification Head
在提取出 cls_token 后,将其输入进分类头,就进入 ViT 的输出部分了。ViT 的分类头是根据预训练或微调的任务特点做了极致的差异化设计,这是 ViT 在视觉任务上实现高泛化性,高微调效率的关键,
预训练阶段使用的是多层感知头,标准设计包括 LN,线性变换,GeLU,Dropout和再一次线性变换。预训练通常基于超大规模数据集,类别数多、数据分布复杂,需要稍复杂的非线性映射,让模型学习到更泛化的全局视觉特征,避免欠拟合;增加 LayerNorm 是为了对 cls_token 特征做归一化,提升特征分布的稳定性,适配大规模预训练的训练波动。
微调阶段使用单一线性层,预训练后的 cls_token 已经聚合了通用的全局视觉特征,微调仅需简单的线性映射,就能将通用特征适配到具体任务的类别空间,无需非线性变换。
Swin Transformer
在上面我们知道,经典的 ViT 最后导出 cls_token,其对图像全局信息的把控是到位的,但却可能无法有效捕捉局部特征,Swin Transformer 便采用窗口和分层的形式来替代长序列的方法。我们可以将当前这件事做
基于移位窗口的多头自注意力模块 W-MSA / SW-MSA
W-MSA 相比 MSA 就是将一个 Patch 划分为若干窗口,每个窗口独立计算注意力,其缺点明显,那就是窗口间的关联性不大。
所以窗口需要移位,也就是 SW-MSA(Shifted Window MSA),与 W-MSA 相比,区别在于划分窗口时不在时等大小的窗口,而是将划分窗口同时向右和向下平移
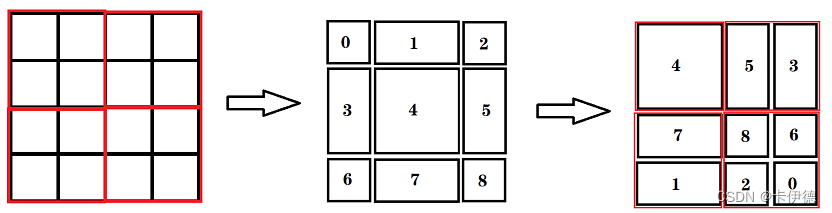
在上图中,左边为 W-MSA 得划分方法,中间为 Shifted Window 划分后的块,每个块进行了