Function describes the world.
联结主义
一切问题都可以用函数进行表示,这里的函数是广义上的函数,即
而 AI 的作用就是通过
最简单的拟合就是线性拟合,也就是高中学过的线性回归
激活函数
所以我们使
这里的
函数: ,可以将 转化为 。 函数: 可以解决梯度消失的问题。 函数: ,归一化指数函数,映射为一个总和为 的概率分布向量。
神经元与神经网络
当然,输入值不一定会有一个,输出值也不一定只有一个,激活函数也不止一个,所以我们可以将其表示为:
其中
加入我们提取其中某个激活函数,将其视为
神经元即转化关系组成神经网络。从一个输入层到输出层的转化称为一次前向传播(Forward)。
神经网络大多都是多层感知机(MLP,Multilayer Perceptron)。
拟合与损失函数
那么,如何得到所有的
然后你也知道绝对值不甚美观,所以我们提出了均方误差(MSE)的概念:
所以,越优秀的拟合函数,意味着
反向传播
我们可以对
也就是
这里的
直接对复合函数求偏导是极其困难的,但是我们会求
我们可以通过:
然后你会发现
训练调整
鲁棒性
如果训练出的模型仅对训练数据具有极强的拟合,而在处理非训练数据时表现很烂,这意味着这个模型陷入了过拟合。反之,如果模型对任何数据都有一定拟合但表现都不尽人意,这意味着这个模型欠拟合。
这种模型的拟合能力,官方名为鲁棒性(Robustness),指一个系统、模型或算法在面对干扰、异常输入或不确定性因素时,仍能维持核心功能稳定运行的能力。
模型调整
数据增强
我们可以通过对训练数据进行一定的处理或增加训练数据来增强鲁棒性,如对于图像训练集,我们可以通过翻转,反色,增噪等方式扩充训练集,这种方式称为数据增强。
正则化
在多数情况下,过拟合的出现源于某几个参数的野蛮生长,即存在
我们将
Dropout
在每一轮训练中随机无视一部分参数。
卷积神经网络,CNN
对于层与层之间,设
记为:
我们将神经网络中的第
层与卷积
如果
所以说,如果神经网络里所有层都是全连接层,则每一次训练的是时空复杂度达到
对于矩阵
简单说就是对应位置乘积。
所以,在图像处理神经网络中,如果我们将分辨率为
那么这一层就被称为卷积层(Conv),
因此,我们可以写出卷积神经网络(CNN)的基本架构:
CNN 一般用于图像处理。
感受野(Receptive Field)
在卷积神经网络中,感受野(Receptive Field)是指特征图上的某个点能看到的输入图像的区域,即特征图上的点是由输入图像中感受野大小区域的计算得到的。神经元感受野的值越大表示其能接触到的原始图像范围就越大,也意味着它可能蕴含更为全局,语义层次更高的特征;相反,值越小则表示其所包含的特征越趋向局部和细节。
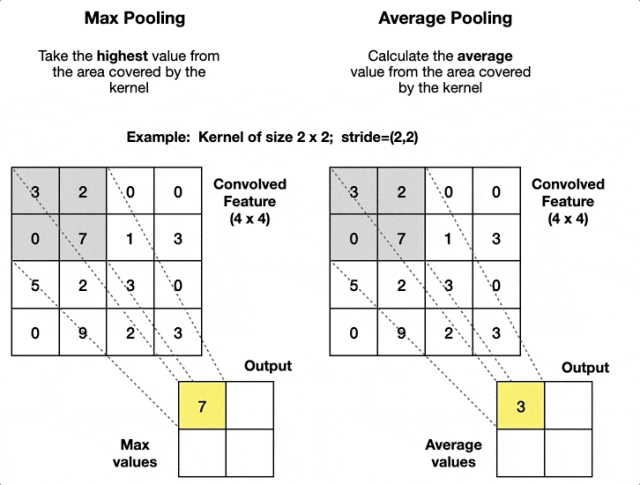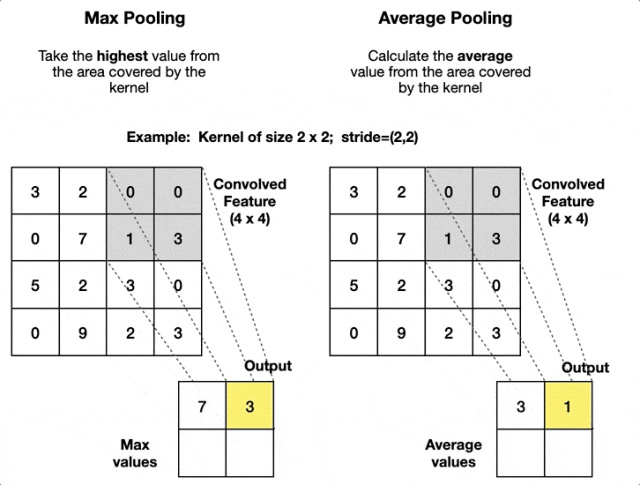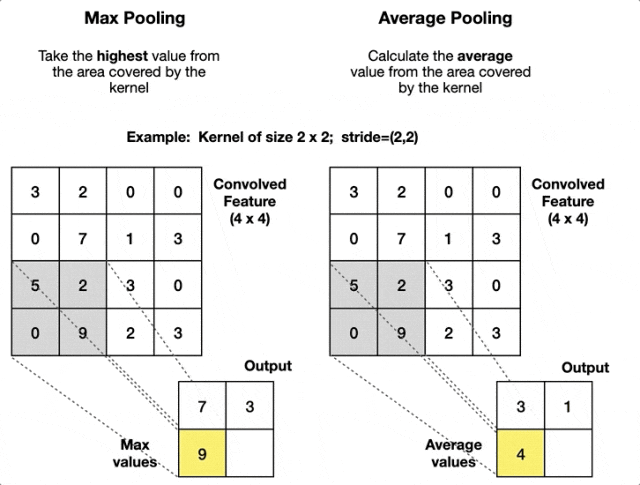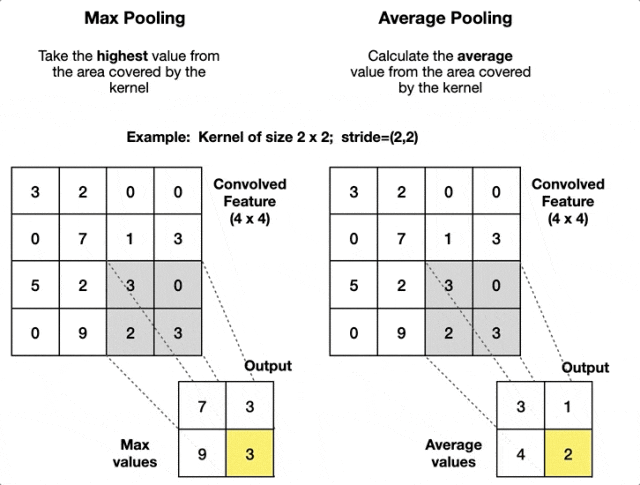
池化
池化是卷积神经网络中的一种下采样操作。它通过定义一个空间邻域(通常为矩形区域),并对该邻域内的特征进行统计处理(如取最大值、平均值等),从而生成新的特征图。池化操作通常紧随卷积层之后。
- 最大值池化:在定义的池化窗口内,选取所有元素中的最大值,并将该最大值作为池化结果输出到下一层特征图的对应位置。
- 平均池化:在定义的池化窗口(如
等)内,计算所有元素的平均值,并将该平均值作为池化结果输出到下一层特征图的对应位置。
池化的重要参数是窗口大小和步长,前者决定操作的区域大小,后者决定滑动距离。
循环神经网络,RNN
在处理自然语言的模型中,将文字转化为向量并不容易,如果每一个字都作为一个单位向量,那么所有向量正交,且万维向量毫无意义,计算量巨大,这种独热编码(One Hot)并不优秀。
Word2Vec
我们将所有词向量限制在一个
Word2Vec 基于假设“在文本中,词语距离越近,相似度越高”,我们首先知道这是不完全正确的,但是具有一定拟合性。通过 CBOW(上下文词推测中心词)和 skip-gram(中心词推测上下文词)两种方式进行训练可以得到一个词库的词向量。
当然,Word2Vec 的局限性很大,首先也是最重要的就是其无法处理多义词,并且其上下文窗口(即规定上
词嵌入(Embedding)
将所有词向量组成一个
循环神经网络
如果输入层包含整个句子,那么输入层大小就会变成
所以考虑每一次传入只传入一个词,我们将第
为了考虑词语在句子中的顺序关系,我们让转移具有一定前缀性,即将
令
简化来讲,即:
计算公式: